7 Apify alternatives, compared on real per-request cost

The best Apify alternative depends on what you're actually escaping: the pricing model, the maintenance risk, or the do-it-yourself overhead. Route by need: structured data with the USD price shown before you call goes to AnyAPI; LLM-ready page content goes to Firecrawl; raw HTML at volume goes to ScraperAPI or ScrapingBee; enterprise proxy networks go to Bright Data; and if you want to own the whole stack, use Crawlee. I priced a 1,000-page job on every vendor that publishes a usable per-request number, and the rest you can only price as a range after the job runs.
You picked Apify so you wouldn't have to build and babysit scrapers. Now the bill needs a spreadsheet: a platform plan, compute units metered by RAM and time, storage and data transfer, and on top of all that, each store actor's own rental or per-result fee.
And the inputs keep changing. Prices differ per actor, unused prepaid credits don't roll over to next month, and a community actor can slip "under maintenance" and take your pipeline down with it.
So I went through 7 alternatives using their own published pricing pages, and compared what each one says a job costs against what you'd actually pay.
The advertised price and the real bill are two different numbers, and on several of these platforms you can't know the real one before you run the job.
Why people leave Apify
The two complaints I hear are the same two you can read straight off Apify's own pages: you can't predict the cost, and you can't count on a community actor staying alive. Both come from apify.com/pricing and the Apify docs.
Start with the bill, because it's built in layers and every layer meters differently:
| Layer | What meters it | Published rate |
|---|---|---|
| Platform plan | Your monthly usage budget | $5 free, then $29 / $199 / $999 per month |
| Compute units | 1 GB of RAM for 1 hour, per actor run | $0.20 per CU on Free and Starter, down to $0.13 on Business |
| Actor fee | The store actor's own rental price, set by its author | Varies per actor |
| Storage + transfer | Datasets, key-value stores, proxy data moved | Metered pay-as-you-go |
The bottom layer is the platform plan, and the included usage on each paid plan equals the plan price. That's your usage budget, not a flat fee on top of usage.
The next layer is compute units. A heavy browser actor chewing through pages burns CUs fast, and how many it burns depends on the actor's code, not on you.
Then comes the layer most cost estimates miss: the store actor itself. Many actors in the Apify Store carry their own monthly rental fee on top of the platform usage they consume. So one scraping job can bill you the plan, the compute it ran, the storage and data transfer it moved, and the actor's own rent, all at once.
And the credits that pay for all of it expire. Apify's pricing page is explicit: unused usage credits are not rolled over to the next billing cycle. Whatever budget you don't spend this month is gone.
Cost is only half of it. Store actors run automated tests daily, and an actor that doesn't pass them at least twice in the last three days gets labeled "under maintenance." When you're renting a community developer's actor, you inherit that clock. If they stop maintaining it, your pipeline is the thing that breaks.
I want to be fair about what Apify does well, because it's real. The Apify Store has thousands of pre-built actors, the biggest catalog of ready-made scrapers I know of, so for a long tail of sites there's already an actor that works. And Crawlee, their open-source scraping framework, is genuinely good, good enough that plenty of teams who never touch the platform still build on it.
The catalog and the framework aren't the complaint. The complaint is that one job can bill through four meters at once, and one of those meters is a stranger's code you're renting.
The 7 alternatives
Here's each one in the same shape: what it is, the pricing I verified on the vendor's own page, who it fits, and where it falls down. I'm ordering them roughly from structured data to raw HTML to do-it-yourself, not best to worst.
AnyAPI
Full disclosure: this one's mine. AnyAPI is a marketplace of normalized structured-data APIs (social, commerce, real estate, SERP) behind one key and one USD wallet. You pay per successful request in real dollars, and the price in $/1k is printed on every catalog page before you call anything (a few endpoints also price per result returned, and the catalog page says so up front). See how pricing works.
The point is normalization. Every endpoint returns the same shape whether the request under the hood hit provider A or provider B, so a swap doesn't rewrite your parser. If one upstream breaks mid-job, the gateway fails over to another lane automatically. It's MCP-native, and an agent can sign itself up and pay per call with no human in the loop.
Who it fits: you want a specific platform's data (a Reddit search, a TikTok profile, product listings) and you'd rather not run scrapers or babysit a credit balance. If a straight head-to-head is all you need, I wrote up Apify vs AnyAPI separately.
The weak spot, stated plainly because this one's mine: it's built for structured platform data. If your job is "fetch the raw HTML of an arbitrary URL at proxy scale," the general-purpose unblockers below fit better; AnyAPI doesn't fetch arbitrary raw HTML.
Firecrawl
Firecrawl turns any URL into LLM-ready markdown or JSON. You give it a page, it gives you clean text, and JavaScript rendering is included by default.
Pricing, from Firecrawl's pricing page: a free tier of 1,000 credits a month with no card, then Hobby at $16 a month billed yearly for 5,000 pages. A scrape or crawl costs 1 credit per page, so JS rendering doesn't cost extra the way it does on the proxy vendors. That works out to about $3.20 per 1,000 pages on Hobby.
Who it fits: you're feeding a model and you want the readable content of a page, not the DOM. It's the cleanest option for RAG and agent-reading workflows.
The weak spot: it does whole-page extraction. There's no per-platform primitive, so "give me this Amazon product's price and reviews as fields" is still your parsing job on top of the markdown.
ScraperAPI
ScraperAPI is a proxy and unblocker API: send a URL, it rotates proxies, runs a headless browser if you ask, and returns raw HTML.
Pricing, from ScraperAPI's pricing and docs: the Hobby plan is $49 a month for 100,000 API credits, and the price of one request depends on both the target and the options. A plain page is 1 credit, but Amazon is 5, Google is 25, LinkedIn is 30, render=true for JavaScript is 10, and ultra_premium proxies are 30. So a JS-rendered page on an ordinary site burns 10 credits, which is $4.90 per 1,000 rendered pages on Hobby, and the same request against a protected domain costs multiples of that.
Who it fits: high volume of raw HTML where most of your targets are plain pages that stay at 1 credit.
The tradeoff: you still write and maintain the parser, and the credit multipliers make the effective price hard to predict before you know how many of your pages need rendering or premium proxies. I ran this exact comparison against ScrapingBee in a head-to-head benchmark if you want the measured numbers.
ScrapingBee
ScrapingBee is the same category as ScraperAPI, and simpler about it. One call, raw HTML back, proxies and browser handled.
Pricing, from ScrapingBee's pricing and docs: the Freelance plan is $49 a month for 250,000 credits. A basic request is 1 credit, JavaScript rendering is 5, a premium proxy is 25, and stealth is 75. A JS page at 5 credits on the entry plan is about $0.98 per 1,000, which is the cheapest raw-HTML price in this list.
Who it fits: predictable raw-HTML scraping where you'd rather read a short credit table than a long one. Its flat 5-credit JS rate is easier to budget than ScraperAPI's domain-tiered credits.
The weak spot: it's still the credit-multiplier model, so protected sites at 25 or 75 credits change your effective price fast, and you still parse the HTML yourself. When I tested both on the same sites, they tied on success rate and split on speed and price.
Zyte API
Zyte API is a proxy and extraction API with a pricing model built around per-site difficulty tiers instead of a flat credit table.
Pricing, from Zyte's docs: there are 5 tiers each for HTTP and for browser requests, and the rate per successful response climbs with how hard the site is to reach. On pay-as-you-go, an easy HTTP request starts around $0.13 per 1,000, and browser rendering runs from about $1 up past $16 per 1,000 on the hardest tier.
Who it fits: teams that want Zyte to absorb the anti-bot problem and are fine letting the price float with site difficulty.
The tradeoff: the tier is assigned automatically and can change on review, so you can't know a site's tier, and therefore its price, before you run against it. Easy targets are genuinely cheap; hard ones are not, and you find out which after the fact.
Bright Data
Bright Data is an enterprise proxy network with scraper APIs layered on top. Its Web Scraper API returns structured records from supported sites.
Pricing, from Bright Data's Web Scraper page: pay-as-you-go is $1.50 per 1,000 records, with a free tier of 5,000 records a month and a Scale plan at $499 a month that drops the rate to $1.30 per 1,000 additional records. You pay only for records that are delivered.
Who it fits: enterprise volume with compliance and KYC requirements. At real scale with a legal team involved, this is the one I'd shortlist.
The weak spot: the enterprise overhead (KYC, account review, the sales motion) is overkill for a small job, and the per-record model assumes the site is one Bright Data already supports.
Crawlee
Crawlee is the open-source answer, and it's Apify's own Apache-2.0 framework for building scrapers in Node or Python. It's genuinely good: queue management, proxy rotation, browser and HTTP crawlers, anti-blocking, all in one library.
Pricing: free. It's Apache-2.0, so there's no per-request cost at all.
Who it fits: you want to own the stack, you have infra, and you'd rather write and run the scraper than pay per call.
The tradeoff: it's do-it-yourself. Crawlee gives you the framework, but you still buy proxies, run the infrastructure, and fix every site that breaks. It replaces Apify the platform; the scraping work is still yours.
What 1,000 requests actually cost
Here's one job, 1,000 JavaScript-rendered pages on an ordinary site, priced from each vendor's published entry-plan numbers. I'm stating every assumption inline so you can check it.
Firecrawl bundles JS, so 1,000 pages is 1,000 credits, which at $16 for 5,000 pages is $3.20. ScrapingBee charges 5 credits per JS page, so 5,000 credits out of the 250,000 on the $49 plan is $0.98. ScraperAPI charges 10 credits per rendered page, so 10,000 credits out of the 100,000 on the $49 plan is $4.90. Bright Data's Web Scraper API is $1.50 per 1,000 records pay-as-you-go, if your target is a site it supports (a record, not a raw page, so it's the loosest fit in this comparison). Those four I can price cleanly, though note Firecrawl's 1,000 free monthly credits and Bright Data's 5,000 free monthly records would each cover this job once before you pay anything.
The other two don't give you a number in advance at all.
Zyte assigns a difficulty tier per site automatically, and browser rendering spans roughly $1 to $16 per 1,000 depending on that tier. You find out which tier your target sits in once you run against it.
Apify is worse for this, because a compute unit is a unit of time and memory, not of output. A single scrape's cost depends on how long that specific actor runs and how much RAM it holds, and every actor burns compute differently, on top of whatever rental or per-result fee its author set. Two actors scraping the same page can bill wildly different amounts, and nothing on the pricing page tells you which in advance.
So the four you can price cleanly look like this:
Zyte and Apify aren't in the chart because there's no single number to plot. Site-tier and compute-time billing only resolve to a price after the job runs. On several of these platforms you cannot know the price of a job before you run it, and that unpredictability costs you more than the headline rate on the pricing page.
Which one should you pick?
There's no single winner here, because these tools aren't solving the same problem. Match the pick to the job.
Here's how I route it.
| If you need | Pick | Because |
|---|---|---|
| Structured platform data (social, commerce, real estate, SERP) | AnyAPI | Normalized JSON, one key, USD price shown before you call, automatic failover between providers |
| LLM-ready page content from any URL | Firecrawl | Markdown and JSON out of arbitrary pages, priced per successful scrape |
| Raw HTML at proxy scale | ScraperAPI or ScrapingBee | Unblocker plus headless browser, you parse the HTML yourself |
| Enterprise volume with compliance and KYC | Bright Data | Serious proxy network and legal coverage, built for that scale |
| A $0 budget and your own infra | Crawlee | Apache-2.0, you run the servers and buy the proxies |
| An AI agent that pays per call | AnyAPI | MCP-native, agents self-signup and pay per request with no human in the loop |
The split is simple: AnyAPI is for structured data from known platforms, where I've already normalized the schema and can fail over between upstreams. If your job is fetching raw HTML from arbitrary URLs and parsing it yourself, a general-purpose unblocker like ScraperAPI or Bright Data fits better, and if you want to own every layer, Crawlee is the answer. I use the routing above the same way I'd hand it to a teammate: name the job first, then the tool.
The call I actually run
None of the posts ranking for this keyword show any code, and the code is what decides it in practice. Here's a real call to a catalog SKU, searching the top posts in r/homelab this month, and the response from a real run.
curl -X POST https://api.getanyapi.com/v1/run/reddit.search \
-H "Authorization: Bearer $ANYAPI_KEY" \
-H "Content-Type: application/json" \
-d '{"query": "subreddit:homelab", "sort": "top", "timeframe": "month"}'import os, requests
res = requests.post(
"https://api.getanyapi.com/v1/run/reddit.search",
headers={"Authorization": f"Bearer {os.environ['ANYAPI_KEY']}"},
json={"query": "subreddit:homelab", "sort": "top", "timeframe": "month"},
)
for post in res.json()["output"]["posts"]:
print(post["score"], post["title"])const res = await fetch("https://api.getanyapi.com/v1/run/reddit.search", {
method: "POST",
headers: {
Authorization: `Bearer ${process.env.ANYAPI_KEY}`,
"Content-Type": "application/json",
},
body: JSON.stringify({ query: "subreddit:homelab", sort: "top", timeframe: "month" }),
});
const { output } = await res.json();
for (const post of output.posts) console.log(post.score, post.title);{
"output": {
"posts": [
{
"id": "1u4bpps",
"title": "$30 lowball = 12 IBM/Dell Servers. The guy did not know what he had.",
"author": "JustLovett0",
"score": 6110,
"numComments": 486,
"subreddit": "homelab",
"permalink": "/r/homelab/comments/1u4bpps/30_lowball_12_ibmdell_servers_the_guy_did_not/",
"url": "https://www.reddit.com/r/homelab/comments/1u4bpps/30_lowball_12_ibmdell_servers_the_guy_did_not/",
"createdUtc": 1781308652
}
],
"nextCursor": "I49xxlT-6DkIM7Bwz4Cs71..."
},
"provider": "AnyAPI",
"costUsd": 0.002
}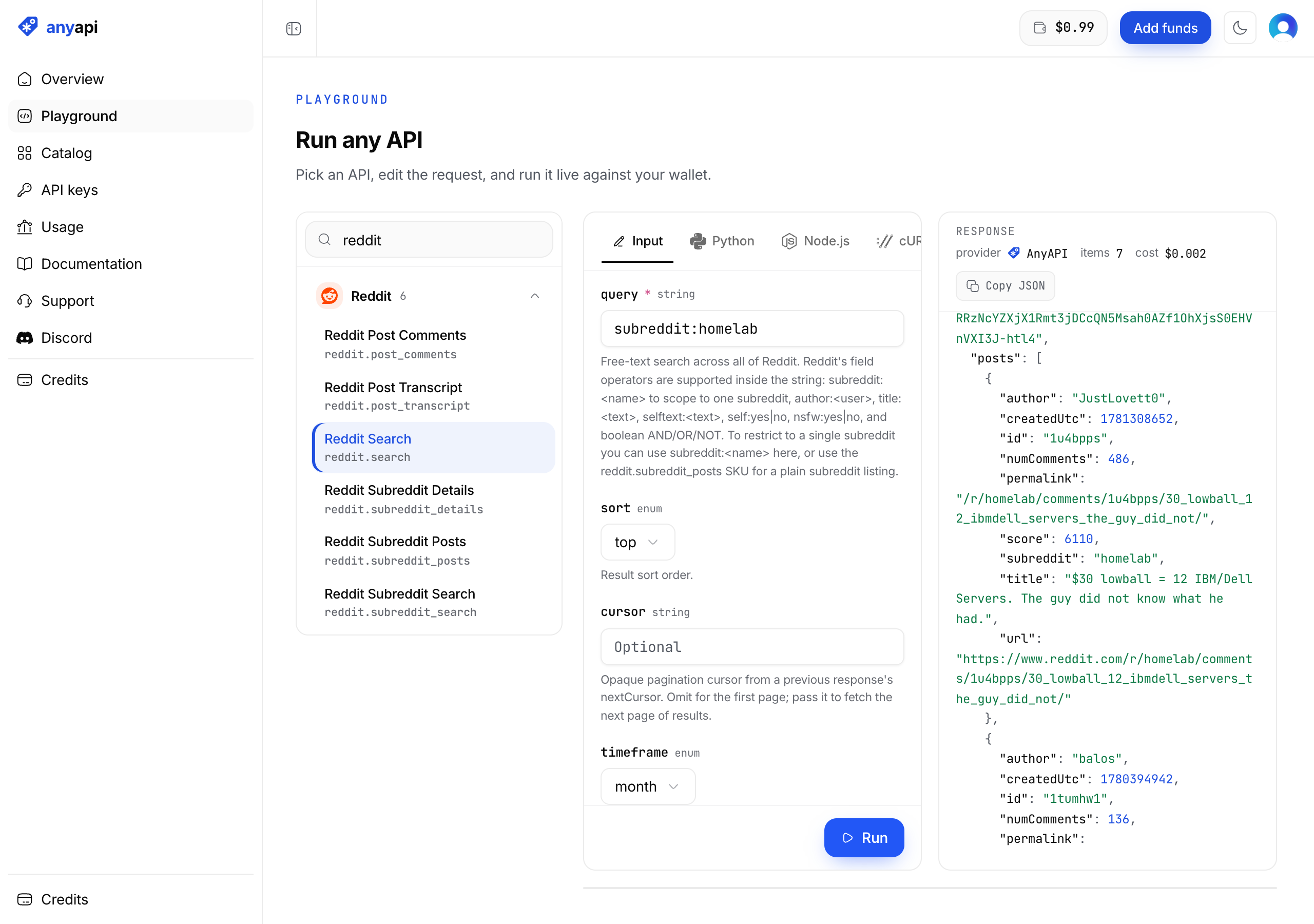
That call costs $0.002, which is $2 per 1,000 requests, the costUsd right there in the response. The shape matters more than the price: you get the same normalized fields back regardless of which upstream provider served the request, so when the gateway fails over from a broken provider to a working one, your parser doesn't change a line.
That same endpoint is callable over MCP, so an agent can reach it as a tool with no glue code. And an agent can sign itself up and pay per call, so there's no human stopping to paste a key mid-run.
Frequently asked questions
Is Apify free?
Apify has a free plan that includes $5 of prepaid platform usage per month, no card required. That $5 covers compute, storage, and proxies at the pay-as-you-go rate, and many per-result actors charge on top of it. For anything beyond light testing you move to a paid plan.
How does Apify pricing work, and what is a compute unit?
You pay a monthly platform plan, and running actors burns compute units, storage, and proxy transfer against it. A compute unit is 1 GB of RAM running for 1 hour, so an actor that needs 4 GB for 15 minutes burns 1 CU. Many actors also add their own rental or per-result fee on top of the compute they consume.
What is the best free alternative to Apify?
For running your own scrapers at $0, Crawlee: it's Apify's own Apache-2.0 framework and it's genuinely good. For getting structured data without running infra, AnyAPI gives new accounts a $1 signup credit and then bills per request in USD. Firecrawl also has a free tier of 1,000 credits for LLM-ready page content.
Is there an open-source alternative to Apify?
Yes. Crawlee (Node and Python) and Scrapy (Python) are the two open-source scraping frameworks people move to. Both are free and self-hosted, which means you buy the proxies, run the servers, and fix the breakage yourself. They replace the platform, not the work of scraping.
What is the cheapest Apify alternative?
At high volume of plain HTML, ScrapingBee's flat per-request credits usually come out cheapest, which I measured in ScrapingBee vs ScraperAPI. For structured platform data with no subscription, AnyAPI is pay-per-request in USD with nothing to expire. The real answer depends on whether you're pulling raw HTML or structured records.
Apify vs ScraperAPI?
Different products. Apify runs full scraper programs (actors) that return structured data; ScraperAPI is an unblocker that fetches raw HTML from a URL and hands you the page to parse. Pick Apify when you want a ready-made actor for a specific site, ScraperAPI when you want proxy and browser handling for URLs you'll parse yourself.
Apify vs Firecrawl?
Apify runs per-site actors that return structured records; Firecrawl turns any URL into LLM-ready markdown or JSON. Firecrawl fits a RAG or agent pipeline where you feed whole pages to a model. Apify fits when you need a specific site's data in a specific shape and there's an actor for it.
Do Apify credits roll over?
No. Unused prepaid usage resets at the end of each billing cycle and doesn't carry forward, on the free plan and paid plans alike. You budget each month's usage as use-it-or-lose-it.
Which alternative works with AI agents or MCP?
AnyAPI is MCP-native, so every catalog endpoint is callable as an agent tool, and an agent can sign itself up and pay per call with no human in the loop. It also settles inline payments over x402, so an agent can buy a single call with no account at all.
Can I get structured data without maintaining scrapers?
Yes, that's what managed data APIs are for. AnyAPI returns structured platform fields, Firecrawl returns extracted page content, and Bright Data's Web Scraper API returns records from supported sites; ScraperAPI and ScrapingBee still leave the parsing to you. With AnyAPI specifically, if one upstream provider breaks on a request the gateway fails over to another, so a broken source doesn't stop your job.
What happens when an Apify actor stops being maintained?
Apify labels an actor "under maintenance" when it fails its automated tests too often over a three-day window. Community-built actors can be abandoned by their developer, and your pipeline inherits that risk. It's worth checking an actor's maintenance status and last update before you build on it.
The short version
The best Apify alternative depends on what you're escaping. If it's unpredictable bills and expiring credits, a pay-per-request API in USD fixes it; if it's the DIY overhead of raw HTML at proxy scale, an unblocker or Crawlee fits better. For structured platform data with one key, automatic failover, and a price you can read before you run the call, browse the catalog: new accounts start with a $1 signup credit, and every endpoint is priced per request in real US dollars with nothing to expire.